到达定值
到达定值
我们可能希望找出在某个程序点上一个变量可能有哪些值,以及这些值可能在哪里定值。考虑下面这段代码:
我们可能对程序点( )上的所有程序状态进行总结: 的值总是 中的一个,而它由 中的一个定值。可能沿着某条路径到达某个程序点的定值称为到达定值(reaching definition)。
到达定值是最常见和有用的数据流模式之一。只要知道当控制到达程序中每个点的时候,每个变量 可能在程序中的哪些地方被定值,我们就可以确定很多有关 的性质。比如,一个编译器能够根据到达定值信息知道 在点 上的值是否为常量,而如果 在点 上被使用,则调试器可以指出 是否未经定值就被使用。
未定值先使用
我们可以在流图的入口处对每个变量 引入一个哑定值(dummy definition)。如果 的哑定值到达了一个可能使用 的程序点 ,那么 就可能在定值之前被使用。请注意,我们永远不能绝对肯定这个程序包含一个错误。因为有可能存在某种原因使得到达 点而没有真正对 赋值的路径实际上并不存在。这个原因可能涉及复杂的逻辑问题。考虑以下程序片段:
int x; // x_dummy if (不透明谓词(一个复杂的数论真命题)) { x = 10; // x_1 } printf("%d\n", x); // x_2分析器可能无法推导分支条件恒为真。实际上,分析器会插入 函数( 函数的作用请参考这里 ):
由于 和 的值一定不同。所以分析器必须假设 和 都可能到达第五行代码。但实际上 未定义的情况永远不会发生,但是编译器根据分析结果将会报告 可能存在未定义被使用。这个反例展示了静态分析的根本局限性,它能识别所有可能的错误路径,但无法确定哪些路径会在实际执行中发生。这就是为什么到达定值分析只能给出“可能存在未定义使用”的警告,而非确定性结论。
到达定值的传递方程
我们为到达定值问题设置约束。首先检查单个语句的细节。考虑一个定值:
在这里 代表一个赋值操作, 表示一个一般性的二元运算符。
这个语句“生成”了一个变量 的定值 ,并“杀死”了程序中其他对 的定值,而进入这个语句的其他定值都没有收到影响。因此,定值 的传递函数可以被表示为
其中 ,即由这个语句生成的定值的集合,而 是程序中对所有其他 的定值。一个基本块的传递函数可以通过把它包含的所有语句的传递函数组合起来而构造得到。假设有两个函数 和 。那么
这个规则可以扩展到由任意多个语句组成的基本块。假设基本块 有 个语句,而第 个语句的传递函数为 ,那么基本块 的传递函数可以写成:
其中
而
和单个语句一样,一个基本块也会生成一个定值集合并杀死一个定值集合。集合 包含了所有在紧靠基本块之后的点上“可见”的该基本块中的定值——我们把他们成为“向下可见”的。在一个基本块中,一个定值是向下可见的,仅当它没有被同一个基本块中较后的对同一变量的定值“杀死”。一个基本块的 集就是所有被块中各个语句杀死的定值的集合。
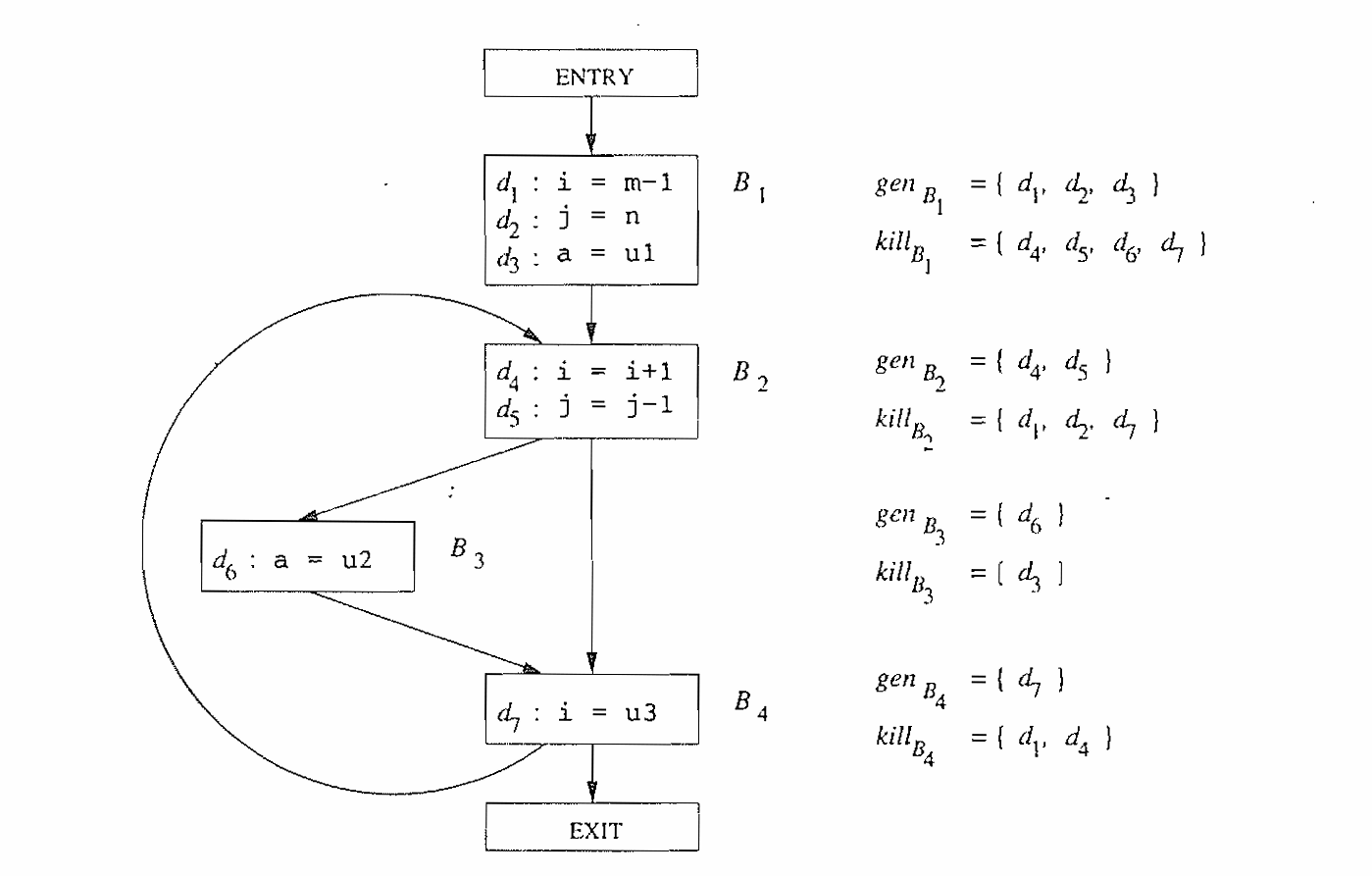
一个定值可能同时出现在基本块的 集和 集中。在这种情况下,该定值会被这个基本块生成,即优先考虑该定值是否在 集中。这是因为在 形式中, 集会在 集之前被使用。
到达定值的格
到达定值的格元素为定义集合的幂集。假设程序中有三个定义 ,我们定义集合 为所有定义的集合 ,格的元素 。即格的所有可能的元素为 。假设需要使用半格 表示到达定值的格,我们设置半格的顶元素 ,底元素 。我们定义 操作为 ,根据定义 ,偏序应该是 。 为半格中的最大元素,而 为半格中的最小元素。因为, 并且 。
操作为 , 为 , 为半格中的最大元素,而 为半格中的最小元素。这可能有点违反直觉,但实际上它仍然是正确的。在有些文献中,到达定值的格为一个并半格 ,它的并操作 为 ,偏序 为 ,最大元素 为 ,最小元素 为 。在到达定值分析中,虽然两种的半格表示都是正确的,但是在初始化和迭代方向上有所不同。
不过在这里我们并不使用并半格的概念,而是使用 表示所有半格。
这个半格的图结构表示如下:
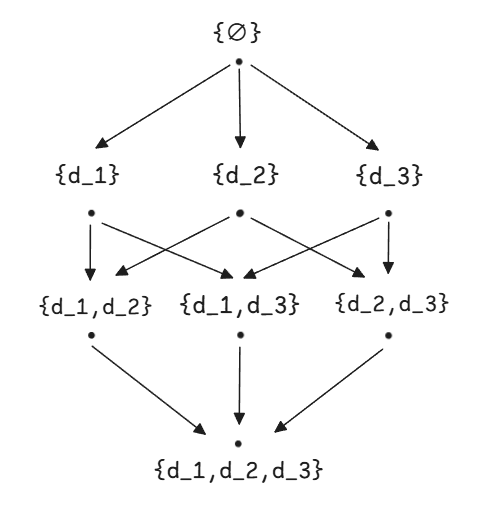
这个格同样是单调性的(如果你不明白单调性的作用,请参考这篇文章 单调数据流分析框架 )。我们知道传递函数的形式为 。当输入定义集增大时,输出集不会减小,验证:
初始值和安全值
我们知道到达定值的格结构为 幂格集,其中 是 ,表示 “无定义到达”,最乐观假设。 是全集 ,表示“所有定义都可能到达”,这是最保守的假设,也是我们优化时最不希望的结果。
到达定值的安全值可以设置为 或者 。根据单调性和不动点定理:到达定值的传递函数是单调的,且格是有限高度的,迭代算法必然收敛到一个不动点。在到达定值中,无论从 还是 开始迭代,最终都会收敛到同一个不动点。这是因为,从 开始(空集):通过传递函数逐步添加定义(),并集合并路径,最终覆盖所有可达定义。收敛速度通常更快(初始值接近最终解),依据标准最小不动点理论。而从 开始(全集):通过传递函数移除不可达定义(),并集保留可达定义,最终收敛到相同结果。收敛速度可能更慢(需多轮迭代移除多余定义),依据最大不动点。
代码示例
class ReachingDefsPowerSetSemilattice(Semilattice[set[DefPoint]]):
def __init__(self, var: Variable, universal_set: set[DefPoint]):
self.var = var
self.universal_set = universal_set
def top(self) -> T:
return set()
def bottom(self) -> T:
return self.universal_set.copy()
def partial_order(self, a: T, b: T) -> bool:
"""
a <= b (a 包含 b)
"""
return b.issubset(a)
def meet(self, a: set[DefPoint], b: set[DefPoint]) -> set[DefPoint]:
"""
并集
"""
return a | b
class ReachingDefsProductSemilattice(Semilattice['Semilattice']):
def __init__(self, defs_block: Dict[BasicBlock, List[Tuple[Variable, DefPoint]]]):
"""
defs_block: 一个字典,键为基本快(BasicBlock类), 值为元组(变量,定义点)的列表。
"""
# 每个变量对应幂集半格
self.var_to_lattice: Dict[Variable, ReachingDefsPowerSetSemilattice] = { }
# 为所有的变量都创建一个幂集半格
self.lattices: List[ReachingDefsPowerSetSemilattice] = []
# 变量在幂集半格列表中的索引
self.tuple_index: Dict[Variable, int] = { }
self._initialize_lattices(defs_block)
def _initialize_lattices(self, defs_block: Dict[BasicBlock, List[Tuple[Variable, DefPoint]]]):
for defs_list in defs_block.values():
"""
遍历每个元组列表
"""
for defs in defs_list:
# 取出变量
var: Variable = defs[0]
# 找到对应的半格
lattice = self.var_to_lattice.get(var)
if not lattice:
"""
如果半格不存在就创建它,并添加到半格列表
"""
lattice = ReachingDefsPowerSetSemilattice(var, set())
self.lattices.append(lattice)
self.tuple_index[var] = len(self.lattices) - 1
self.var_to_lattice[var] = lattice
# 添加定义点到半格的全集
lattice.universal_set.add(defs[1])
def meet(self, a: T, b: T) -> T:
return tuple(
lat.meet(a_i, b_i)
for lat, a_i, b_i in zip(self.lattices, a, b)
)
def top(self) -> T:
return tuple(lat.top() for lat in self.lattices)
def bottom(self) -> T:
return tuple(lat.bottom() for lat in self.lattices)
def partial_order(self, a: T, b: T) -> bool:
return all(
lat.partial_order(a_i, b_i)
for lat, a_i, b_i in zip(self.lattices, a, b)
)
def reaching_definitions(cfg):
"""
执行到达定值分析
"""
defs_block: Dict[BasicBlock, List[Tuple[Variable, DefPoint]]] = cfg.collect_definitions()
lattice = ReachingDefsProductSemilattice(defs_block)
transfer = ReachingDefsTransfer(lattice, defs_block)
analysis = DataFlowAnalysisFramework(
cfg=cfg,
lattice=lattice,
transfer=transfer,
direction='forward',
init_value=lattice.top(),
safe_value=lattice.top(), # 也可以为bottom
on_state_change=reaching_defs_on_state_change
)
analysis.analyze(strategy='worklist')