Performing compile time optimization requires solving a class of problems, called Global data flow analysis problems (abbreviated as gdfap's), involving determination of information which is distributed throughout the program.
Monotone data flow analysis frameworks are used to analyze the flow of information through a program. They are based on the idea of propagating data flow information through the control flow graph (CFG) of the program. The analysis is called "monotone" because the information gathered at each point in the program is monotonically increasing(or decreasing) as the analysis progresses.
Definition: A flow graph is a triple G=(N,E,n0), where:
- N is a finite set of nodes.
- E is a subset of N×N called the edges. The edge (x,y) enters node y and leaves node x. We say that x is a predecessor of y, and y a successor of x.
- n0 in N is the initial node. There is a path from n0 to every node.
Definition: A semilattice is a set L with a binary meet operation ∧ such that for all a,b,c∈L:
a∧a=aa∧b=b∧aa∧(b∧c)=(a∧b)∧cidempotentcommutativeaccociative
Definition: Given a semilattice L and elements, a,b∈L, we say that
a≥b⟺a∧b=ba>b⟺a∧b=b ∧ a=b
also a≤b means b≥a and a<b means b>a. We extend the notation of the meet operation to arbitrary finite sets by saying
1≤i≤n⋀xi=x1∧x2∧...∧xn
Definition: A semilattice L is said to have a bottom element ⊥, if for all $ x \in L, \bot \wedge x = \bot$. L is said to have a top element ⊤, if ⊤∧x=x for all x∈L. We assume from here on that every semilattice has a bottom element, but not necessarily a top element.
Definition: Given a semilattice L, a sequence of elements x1,x2,...,xn in L forms a chain if $ x_i > x_{i-1}$ for 1≤i<n. L is said to be bounded if for each x∈L there is a constant bx such that each chain beginning with x has length at most bx.
If L is bounded, then we can take meets over countably infinite sets if we define x∈S⋀x , where S={x1,x2,...} , to be limn→∞1≤i≤n⋀xi . The fact that L is bounded assures us there is an integer m such that x∈S⋀x=1≤i≤m⋀xi .
Partial Orders and Greatest Lower Bounds
As we shall see, the meet operator of a semilattice define a partial order on the values of the domain. A relation ≤ is a partialorder on a set V if ∀x,y,z∈V :
- x≤x (the partial order is reflexive).
- If x≤y and y≤x , then x=y (the partial order is antisymmetice).
- If x≤y and y≤z , then x≤z (the partial order is transitive).
The pair (V,≤) is called a poset, or partiallyorderedset. It is also convenient to have a < relation for a post, defined as
x<y⟺(x≤y)and(x=y).
Suppose (V,∧) is a semilattice. A greatestlowerbound (or glb) of domain elements x and y is an element g such that
- g≤x,
- g≤y, and
- If z is any element such that z≤xandz≤y,thenz≤g.
It turns out that the meet of x and y is their only greatest lower bound. To see why, let g=x∧y. Observe that:
- g≤x because (x∧y)∧x=x∧y.
- g≤y by a similar argument.
- Suppose z is any element such that z≤x and z≤y. We claim z≤g, and therefore, z cannot be a glb of x and y unless it is also g. In proof: (z∧g)=(z∧(x∧y))=((z∧x)∧y). Since z≤x, we know (z∧x)=z , so (z∧g)=(z∧y). Since z≤y , we know z∧y=z , and therefore z∧g=z. We have proven z≤g and conclude g=x∧y is the only glb of x and y.
Definition: Given a bounded semilattice L, a set of functions F on L is said to be a monotonefunctionspaceassociatedwithL if the following conditions are satisfied:
[M1] Each f∈F satisfies the monotoncity condition,
(∀x,y∈L)(∀f∈F)[f(x∧y)≤f(x)∧f(y)]
[M2] There exists an identify function i in F, such that
(∀x∈L)[i(x)=x].
[M3] F is closed under composition, i.e. f,g∈F⇒f∘g∈F, where
(∀x,y∈L)[f∘g(x)=f(g(x))]
[M4] L is equal to the closure of {0} under the meet operation and application of functions in F.
Observation1. Given a semilattice L, let f be a function on L, then
(∀x,y∈L)[f(x∧y)≤f(x)∧f(y)]⟺(∀x,y∈L)[x≤yimpliesf(x)≤f(y)]
proof. We shall assume (∀x,y∈L)[x≤yimpliesf(x)≤f(y)] and show that (∀x,y∈L)[f(x∧y)≤f(x)∧f(y)] holds. Since x∧y is the greatest lower bound of x and y, we know that
x∧y≤xandx∧y≤y
Thus, by (∀x,y∈L)[x≤yimpliesf(x)≤f(y)],
f(x∧y)≤f(x)andf(x∧y)≤f(y).
Since f(x)∧f(y) is the greatest lower bound of f(x) and f(y), we have (∀x,y∈L)[f(x∧y)≤f(x)∧f(y)].
Conversely, let us assume (∀x,y∈L)[f(x∧y)≤f(x)∧f(y)] to prove (∀x,y∈L)[x≤yimpliesf(x)≤f(y)]. We suppose x≤y and use (∀x,y∈L)[f(x∧y)≤f(x)∧f(y)] to conclude f(x)≤f(y). Since x≤y is assumed, x∧y=x , by definition. We know that
f(x)≤f(x)∧f(y).
Since f(x)∧f(y) is the glb of f(x) and f(y), we know f(x)∧f(y)≤f(y). Thus
f(x)≤f(x)∧f(y)≤f(y)
implies (∀x,y∈L)[x≤yimpliesf(x)≤f(y)].
□
Observation2. For any bounded semilattice L and any countable set S⊆L, if for all x∈S we have x≥y , then x∈S⋀x≥y.
proof. Consider the meet of all elements in S:
m=x∈S⋀x
The meet m is the greatest lower bound of all elements in S. By definition, m≤x for all x∈S. If x≥y for all x∈S, then every element in S is an upper bound for y. m, being the greatest lower bound of all x∈S, must also be a lower bound for y. Therefore, y∈m. Hence, m=x∈S⋀x≥y.
□
Definition: A Monotone data flow analysis framework is a triple D=(L,∧,F), where
- L is a bounded semilattice with meet ∧.
- F is a monotone function space associated with L.
A particular instance of a monotone data flow analysis framework is a pair I=(G,M), where
- G=(N,E,n0) is a flow graph.
- M:N→F is a function which maps each node in N to a function in F.
Some monotone data flow analysis frameworks satisfy the condition:
(∀x,y∈L)(∀f∈F)[f(x∧y)=f(x)∧f(y)](distributivity)
That is, each f in F is a homomorphism on L. There are many interesting gdfap's which are monotone data flow analysis frameworks but which do not satisfy the distributivity property. The following are some examples.
Constant Propagation can be formalized as a monotone data flow analysis framework CONST=(L,∧,F). Here L⊂2V×R, where V={A1,A2,...} is an infinite set of variables and R is the set of all real numbers.
L is the set of functions from finite subsets of V to R.
θ∈L is the function which is undefined for all Ai∈V.
The meet operation on L is set intersection.
Intuitively, z∈L stands for the information about variables which we may assume at certain points of the program flow graph. (A,r)∈z implies the variable A has value r.
We define a notation for functions in F based on the sequence of assignments whose effect they are to model.
- There are functions denoted ⟨A:=BθC⟩ and ⟨A:=r⟩ in F, for each A, B and C in V, r∈R and θ∈{+,−,∗,/}.
Let z∈L. Then
⟨A:=BθC⟩(z)=z′, where z′(X)=z(X) for all X∈V−{A}; z′(A) is undefined unless z(B)=b and z(C)=c for some b and c in R, in which case z′(A)=bθc.
Assume that z represents the semilattice before that the program execution flow enters function ⟨A:=BθC⟩, and z′ the semilattice of the program execution flow after executing ⟨A:=BθC⟩. Since ⟨A:=BθC⟩ is an assignment statement, so no matter what the variable A changes, we always know all other variables will not be affected because the only variable affected is A. Hence we can obtain z′(X)=z(X) for all X∈V−{A}. However, we still can determine the value of A if z(B)=b and z(C)=c for some b and c in R, in which case z′(A)=bθc.
⟨A:=r⟩(z)=z′ where z′(X)=z(X) for all X∈V−{A} and z′(A)=r.
- i∈F, where i(z)=z for all z∈L.
- if f,g∈F then f∘g∈F.
Lemma 1. Let L be a semilattice and f1,f2,...,fn be functions on L. If it is true that (∀x,y∈L)(∀1≤i≤n)[fi(x∧y)≤fi(x)∧fi(y)], then f1∘f2∘...∘fn(x∧y)≤f1∘f2∘...∘fn(x)∧f1∘f2∘...∘fn(y).
proof. fn(x∧y)≤fn(x)∧fn(y) (by assumption). Suppose f1∘f2∘...∘fn(x∧y)≤f1∘f2∘...∘fn(x)∧f1∘f2∘...∘fn(y), then fi−1(fi∘...∘fn(x∧y))≤fi−1(fi∘...∘fn(x))∧fi−1(fi∘...∘fn(y)) (by Observation 1). fi−1(fi∘...∘fn(x))∧fi−1(fi∘...∘fn(y))≤fi−1∘...∘fn(x)∧fi−1∘...∘fn(y) (by assumption). So by simple backward induction on i, the lemma follows.
□
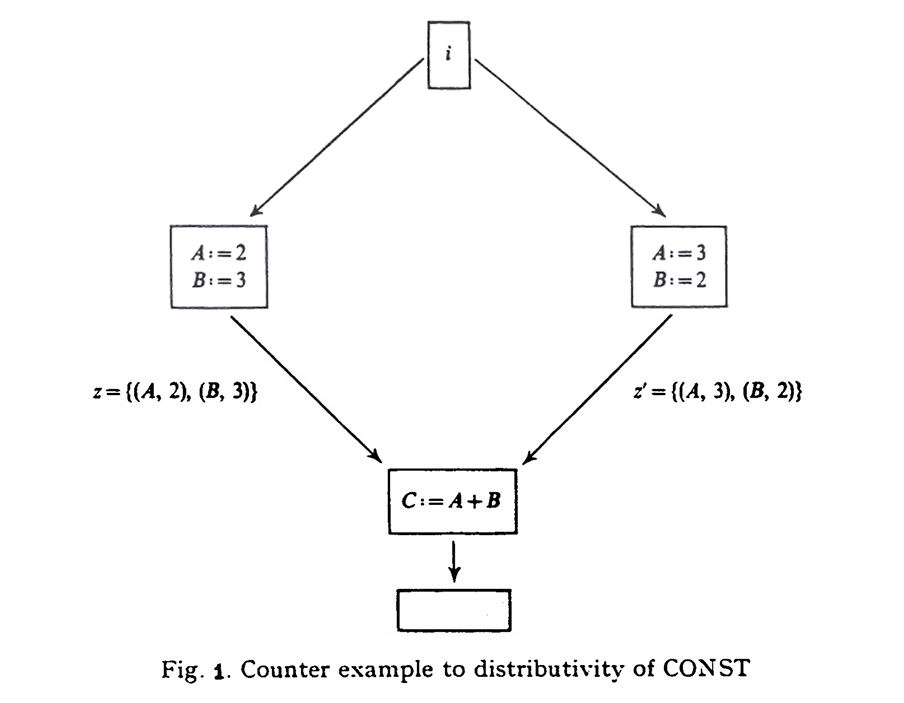
Theorem 1. CONST=(L,∧,F) is a monotone data flow analysis framework. Furthermore there exists z,z′∈L and f∈F such that f(z∧z′)≤f(z)∧f(z′) .
proof. The fact that L is a bounded semilattice with a ⊥ element is obvious. Furthermore, for any element z∈L,z=f1∘f2∘...∘fn(⊥) for some integer n, where fi is of the form ⟨Ai=r⟩. So to show that F is a monotone function space associated with L, it suffices by Lemma 1, to show that for all z,z′∈L and all functions in F of the form ⟨A:=BθC⟩ or ⟨A=r⟩,
⟨A:=BθC⟩(z∧z′)≤⟨A:=BθC⟩(z)∧⟨A:=BθC⟩(z′)
and
⟨A:=r⟩(z∧z′)≤⟨A:=r⟩(z)∧⟨A:=r⟩(z′).
Observe that since ∧ is intersection on L, the ≤ relation is set inclusion.
Suppose we are given z,z′∈L and ⟨A:=BθC⟩∈F. Let y=⟨A:=BθC⟩(z∧z′). Then for all X∈V−{A}, if (X,r)∈y then (X,r)∈z and (X,r)∈z′. Hence (X,r)∈⟨A:=BθC⟩(z) and (X,r)∈⟨A:=BθC⟩(z′).
If A is undefined in y, then we are done. Suppose however, that (A,r)∈y. Then {(B,r1),(C,r2)} is a subset of z and is also a subset of z′, for some r1 and r2 such that r=r1θr2. This implies that (A,r)∈⟨A:=BθC⟩(z) and (A,r)∈⟨A:=BθC⟩(z′)
Suppose we are given z,z′∈L and ⟨A:=r⟩∈F. It is straightforward to show that ⟨A:=r⟩(z∧z′)=⟨A:=r⟩(z)∧⟨A:=r⟩(z′). Hence the first part of the lemma follows.
For a counterexample showing that CONST is not distributive, consider the flow chart of Figure 1. There we see that ⟨C:=A+B⟩(z∧z′)=∅ , while ⟨C:=A+B⟩(z)∧⟨C:=A+B⟩(z′)={(C,5)} .
□
We shall also mention that Theorem 1 can be generalized to any framework whose lattice elements associate "values" with variables, whose meet operation is intersection, and whose functions reflect the application of "operation" on those values and assignment of values to variable. The framework will be monotone in all cases, but will be distributive only if the interpretation of the operator is "free", that is, the effect of applying k-ary operator θ to two different k-tuples of values is never that same.
The phrase "whose functions reflect the application of 'operation' on those values and assignment of values to variable" refers to how the transfer functions in the data flow analysis framework operate on the lattice elements. Specifically, it describes the behavior of these functions in terms of:
- Applying operations to the values associated with variables (e.g., performing arithmetic or logical operations).
- Assigning new values to variables based on the results of those operations.
This means that the transfer functions (f∈F) simulate the effect of program statements on the values of variables. For example:
- If a program statement is
x = y + z, the corresponding transfer function: - Applies the operation + to the values of y and z.
- Assigns the result to x.
In the lattice, this might look this:
- If y is mapped to 3 and z is mapped to 5, the transfer function updates x to 8.
It appears generally true that what one searches for in a data flow problem is what we shall call the meetoverallpaths(MOP) solution. That is, let PATH(n) denote the set of paths from the initial node to node n in some flow graph. The we really want p∈PATH(n)⋀fp(⊥) for each n. It is this function, the MOP solution that, in any practical data flow problem we can think of, expression the desired information.
The paths considered in the MOP solution are a superset of all the paths that are possibly executed. Thus, the MOP solution meets together not only the data-flow values of all the executable paths, but also additional values associated with the paths that cannot possibly by executed.
Notice that in the MOP solution, the number of paths considered is still unbounded if the flow graph contains cycles. Thus, the MOP definition does not lend itself to a direct algorithm. The iterative algorithm certainly does not first find all the paths leading to a basic block before applying the meet operator. Rather,
- The iterative algorithm visits basic blocks, not necessarily in the order of execution.
- At each confluence point, the algorithm applies the meet operator to the data-flow values obtained so far. Some of these values used were introduced artificially in the initialization process, not representing the result of any execution from the beginning of the program.
Algorithm 1 (Essentially Kildall's Algorithm applied to a monotone framework)
Input. A particular instance I=(G,M) of D=(L,∧,F), where G=(N,E,n0) is a flow graph.
Initialization.
(∀n∈N)A[n]{⊥ifn=n0⊤otherwise
IterationStep. Visit nodes other that n0 in order $n_1, n_2, ... $ (with repetitions, and not fixed in advance). We visit node n by setting
A[n]=p∈PRED(n)⋀fp(A[p])
where PRED(n)={p∣(p,n)∈E}. The sequence n1,n2,... has to satisfy the following condition:
If there exists a node n∈N−n0 such that A[n]=p∈PRED(n)⋀fp(A[p]) after we have visited node ns in the sequence, then there exists integer t>s such that nt=n. Also, if after visiting node ns, A[n]=p∈PRED(n)⋀fp(A[p]) for all n=n0, then the sequence will eventually end.
For no loop CFG, the iterative algorithm only iterates once.
Convention. Given instance I=(G,M) of framework D=(L,∧,F), if we apply Algorithm 1 to I with the sequence n1,n2,..., we say that the j-th step of Algorithm 1 has been applied after we have visited node n1,n2,...,nj. Let n be a node in G. We let A(m)[n] denote the value of A[n] right after step m of Algorithm 1 has been applied.
Convention. Given a particular instance I=(G,M) of D=(L,∧,F), we let fn denote M(n), the function in F which is associated with node n. Let P=n1,n2,...,nm,nm+1 be a path in G. Then we may use fP(.) for fnm(fnm−1(...fn1(.))). Note that fnm+1 is not in the composition.
Lemma 2. Given an instance I=(G,M) of a monotone data flow analysis framework D=(L,∧,F), if we apply Algorithm 1 to I, the algorithm will eventually halt.
Proof. It is a simple proof by induction on m, the number of steps applied in Algorithm 1, that A(m+1)[n]≤A(m)[n] (by monotone property, f(x∧y)≤f(x)∧f(y)), for all nodes in G. According to the condition on the sequence of nodes being visited, after we have applied the k-th step of Algorithm 1, either there exists an integer j such that A(k+j+1)[n]≤A(k+j)[n] for some node n in G, or the sequence will halt. The facts that L is bounded and that G has only finitely many nodes guarantee that the sequence ends and the algorithm will eventually halt.
□
Theorem 2. Given an instance I=(G,M) of framework D=(L,∧,F), after we have applied Algorithm 1 to I, we have (∀n∈N)[A[n]≤P∈PATH(n)⋀fP(⊥)], where PATH(n)={P∣Pis a path inGfromn0ton}.
Proof. We want to prove by induction on l that (∀n∈N)(A[n]≤P∈PATHl(n)⋀fp(⊥)), where PATHl(n)={P∣Pis a path of length l from n0 to n}.
Basic. (l=⊥) n0 is the only node that has a path from n0 of zero length. Since A[n0] is assigned ⊥ initially and not changed afterward, the basic holds.
Inducitonsstep. (l>0) If n=n0, we are done. Suppose n=n0. We have A[n]=p∈PRED(n)⋀fp(A[p]) , and (∀p∈PRED(n))(A[p]≤Q∈PATHl−1(p)⋀fQ(⊥)), by hypothesis. Thus A[n]≤P∈PRED(n)⋀fp(Q∈PATHl−1(p)⋀fQ(⊥)) by monotonicity and Observation 1. By monotonicity again, we have A[n]≤p∈PRED(n)Q∈PATHl−1(p)⋀fp(fQ(⊥))=P∈PATHlfP(⊥)⋀. By Observation 2, we have for all n∈N
A[n]≤P∈PATH(n)⋀fP(⊥).
□
Theorem 3. Given an instance I=(G,M) of a monotone framework D=(L,∧,F), after we have applied Algorithm 1, the solution A[n]'s we get is the maximum fixed point solution of the set of simultaneous equations
X[n0](∀n∈X−n0)(X[n]=⊥=p∈PRED(n)⋀fp(X[p])
Proof. It is obvious that, after Algorithm1 halts, the A[n]'s satisfy the above equations. Now suppose we are given any solution B[n]'s to the equation. We want to prove by induction on m, the number of steps applied in Algorithm 1, that after the m-th step B[n]≤Am[n] for all n∈N.
Basic. (m=0) Obvious.
Inductionsstep. (m=0) At the m-th step, we have
Corollary. Given an instance I=(G,M) of a framework D=(L,∧,F), as input to Algorithm 1, the A[n]'s we get after Algorithm 1 halts is unique independent of the sequence in which nodes are visited, provided the sequence satisfies the condition stated in the algorithm.
Theorem 4. Given a monotone framework D=(L,∧,F), suppose (∃x,y∈L)(∃f∈F)[f(x∧y)<f(x)∧f(y)], i.e. D is not distributive. Then there exists an instance I=(G,M) such that after we apply Algorithm 1, there is a node n in G such that
A[n]<P∈PATH(n)⋀fP(⊥).
Proof. By condition [M4] in the definition of a monotone function space, we can find acyclic graphs Gx and Gy, with input nodes nx and ny, and output nodes mx and my, such that after that we apply Algorithm 1 to Gx and Gy, we get A[mx]=x and A[my]=y. A straightforward induction on the number of meet operations and function applications necessary to construct a lattice element from ⊥ proves the existence of Gx and Gy.
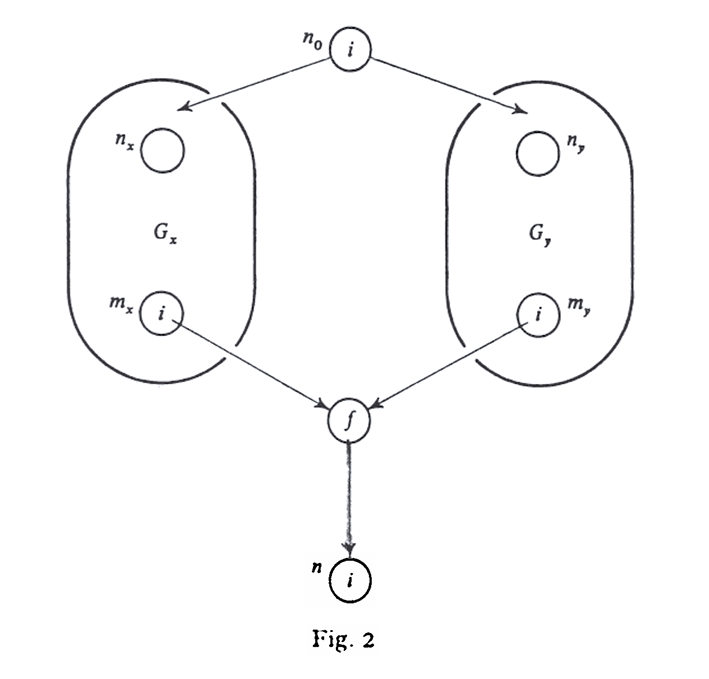
Consider the graph G of the above figure. It is easy to check that if we apply Algorithm 1 we have A[n]=f(x∧y). By Theorem 2, in G we have x≤P∈PATH(nx)⋀fP(⊥) and y≤P∈PATH(ny)⋀fP(⊥). Thus P∈PATH(n)⋀fP(⊥)≥f(x)∧f(y) by monotonicity. But we are given f(x)∧f(y)>f(x∧y), so A[n]<P∈PATH(n)⋀fP(⊥).
□
In summary then, Kildall's algorithm applied to a monotone data flow analysis framework yields a unique solution, independent of the order in which nodes are visited. This solution is the maximum fixed point of the set of equations associated with a flow graph. However, we can only show that the solution is equal to or less than the MOP solution, and when the framework is not distributive there will always be some instance in which the inequality is strict.
A Variant of Kildall's Algorithm
This algorithm will obtain the MOP solution in certain situations where Algorithm 1 fails to do so. However, like Algorithm 1, it must fail for some instance of any monotone, non-distributive framework. It is interesting, however, to note that the two algorithms differ in their behavior in the general monotone case, although they are easily shown in produce identical answers for distributive frameworks.
Algorithm 2
Input. As in Algorithm 1
Initialization
(∀n∈N)B[n]={fn0(⊥)⊤if n=n0otherwise
Iterationstep. Visit nodes other than n0 in order n1,n2,... (not fixed in advance). We visit node n by setting
B[n]:=p∈PRED(n)⋀fn(B[p])
The sequence n1,n2,... has to satisfy the condition: if there is a node n∈N−{n0} such that B[n]=p∈PRED(n)⋀fn(B[p]) after we have visited node ns in the sequence, then there exists integer t>s such that nt=t. Also if B[n]=p∈PRED(n)⋀fn(B[p]) for all n=n0, we will eventually halt the iteration.
FinalStep. We set
H[n0](∀n∈N−{n0})H[n]=⊥=p∈PRED(n)⋀B[p].
Theorem 5. Given an instance I=(G,M) of a framework D=(L,∧,F) as input to Algorithm 2:
Algorithm 2 will eventually halt. The result we get is unique independent of the order in which nodes are visited and (∀v∈N)H[n]≤P∈PATH(n)⋀fP(⊥).
The resulting B[n]'s form the maximum fixed point of the set of equations
X[n0](∀n∈N−{n0})(X[n]=fn0(⊥)=p∈PRED(n)⋀fn(X[p])).
If A[n] is the result of applying Algorithm 1 to I=(G,M), then A[n]≤H[n].
Proof. The proofs are similar to the proofs of the results in the previous section and we omit them.
□
Theorem 6. Given a monotone framework D=(L,∧,F), suppose (∃x,y∈L)(∃f∈F)[f(x∧y)<f(x)∧f(y)], i.e. D is not distributive. Then:
there exists an instance I=(G,M) such that there is a node in G such that
H[n]≤P∈PATH(n)⋀fP(⊥)
after we have applied Algorithm 2 to I.
there exists an instance I′=(G′,M′) such that there is a node n in G′ such that
A[n]≤H[n]
after we have applied Algorithm 1 and Algorithm 2 to instance I.
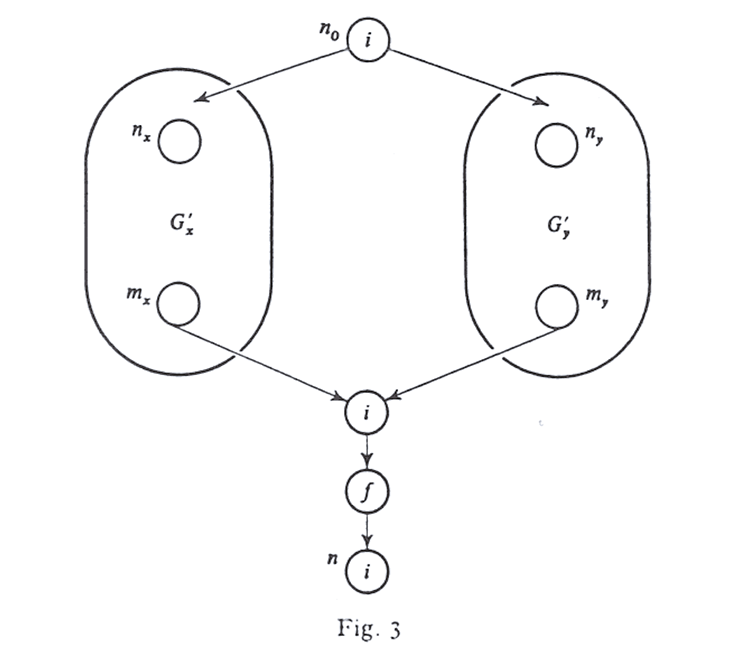
Proof. We may, as in Theorem 4, invoke condition [M4] to observe that there are graphs Gx′ and Gy′ such that their output nodes mx and my have B[mx]=x and B[my]=y. Then consider the graph of the above figure. It follows from monotonicity that
P∈PATH(n)⋀fP(⊥)≥f(x)∧f(y)>f(x∧y)=H[n].
To prove Theorem 6 (2), we refer to Figure 2. Direct calculation will show that A[n]=f(x∧y). By part (3) of Theorem 5, H[mx]≥x and H[my]≥y. Thus B[mx]≥x and B[my]≥y. It follows that H[n]≥f(x)∧f(y), so A[n]<H[n].
□
We have seen that some of the obvious algorithms fail to compute the MOP solution for an arbitrary monotone framework. We shall now show that this situation must hold for any algorithm. In particular, we show that there does not exist an algorithm which, for arbitrary instance I=(G,M) of an arbitrary monotone data flow analysis framework D=(L,∧,F), will compute P∈PATH(n)⋀fP(⊥) for all nodes n of G.
Definition. The ModifiedPost′sCorrespondenceProblem(MPCP) is the following: Given arbitrary lists A and B, of k strings each in {0,1}+, say
A=w1,w2,...,wkB=z1,z2,...,zk
does there exist a sequence of integers i1,i2,…,ir such that
w1wi1wi2…wir=z1zi1zi2…zir
It is well known that MPCP is undecidable.
Example instance of MPCP. Consider the following two lists:
A={w1,w2,w3,w4} and B={z1,z2,z3,z4}
w1=010w2=0w3=01w4=110z1=010z2=100z3=00z4=11
A solution to this problem would be the sequence (4,3,4,2), because
w1w4w3w4w2=010⋅110⋅01⋅110⋅0=010110011100=010⋅11⋅00⋅11⋅100=z1z4z3z4z2
Furthermore, since (4,3,4,2) is a solution, so are all of its "repetitions", such as (4,3,4,2,4,3,4,2), etc.; that is, when a solution exists, there are infinitely many solutions of this repetitive kind.
Association of Post Correspondence Problem with Monotone Data Flow Analysis Frameworks
To associate PCP with monotone data flow analysis frameworks, we can think of the problem in terms of data flow through a hypothetical program. Here's how:
- Control Flow Graph (CFG): Construct a CFG where each node represents a step in the PCP process (e.g., selecting an index from the lists).
- Data Flow Information: Define data flow information that represents the partial solutions to the PCP at each node. For example, at each node, we can track the current concatenation of strings from both lists.
- Monotone Propagation: Propagate this data flow information through the CFG. At each node, update the data flow information based on the selected index and the current concatenation.
- Termination Condition: Check if the data flow information at any node matches the target concatenation. If it does, a solution to the PCP has been found.
Given an instance AB of MPCP with lists A=w1,…,wk and B=z1,…,zk, we can construct a monotone data flow analysis framework DAB=(LAB,∧,FAB), where the following elements are in LAB:
- ⊥, the lattice zero,
- the special element $, which will in a sense indicate non-solution to MPCP, and
- all strings of integers 1,2,…,k beginning with 1.
The meet on these elements in given by: x∧y=⊥ whenever x=y. Thus, if x≤y, then either x=y or x=⊥.
The set of functions FAB includes the following.
the identify function on LAB
functions fi, for 1≤i≤k defined by:
- if a is a string of integers beginning with 1, then fi(a)=ai,
- fi(⊥)=(⊥) and
- fi($)=$,
the function g defined by
- for string a=1i1i2…im,
g(a)={⊥if1i1i2…imis a solution to instance AB of MPCP$otherwise,
- g(⊥)=⊥,
- gi($)=$,
the function h defined by h(x)=⊤ (that is, the string consisting of ⊤ alone) for all x∈LAB .
All functions constructed from the above by composition.
Lemma 3. DAB=(LAB,∧,FAB) constructed above is a monotone data flow analysis framework.
Proof. We show only monotonicity; the other properties are easy to check. By Observation 1 and Lemma !, it suffices to show that if x≤y for x and y in LAB then
- fi(x)≤fi(y) for 1≤i≤k ,
- g(x)≤g(y), and
- h(x)≤h(y).
Since h(x)=h(y)=⊤, (3) is immediate. We have observed that for the meet operation we have defined, x≤y implies x is either y or ⊥. In the former case (1) and (2) are immediate.
In the latter case, fi(x)=⊥ and g(x)=⊥, so fi(x)≤fi(y) and g(x)=g(y) follows.
Theorem 7. There does not exist an algorithm A with the following properties.
- the input to A is
- Algorithms to perform meet, equality testing and application of functions to lattice elements for some monotone framework and,
- An instance I of the framework.
- The output of A is the MOP solution for I.
Proof. If A exists, then we can apply A to any monotone framework DAB constructed above with the instance I. The MOP solution to that problem at point p is easily seen to be $ if the instance AB of the MPCP has no solution, and ⊥ if it does. Thus, if A existed, we could solve the MPCP.
We can construct a CFG where each node represents selecting a index from MPCP lists, and data flow information represents the partial solutions to the MPCP at each node. If the data flow information obtained from different paths is different (which means there is no solution to this MPCP) , then we always obtain ⊥ by definition of meet operator (meet on these elements in given by: x∧y=⊥ whenever x=y. Thus, if x≤y, then either x=y or x=⊥.). By definition of function g, therefore we obtain $, which will in a sense indicate non-solution to MPCP.
- Kam, J.B. and Jeffrey D. Ullman. Monotone Data Flow Analysis Frameworks, Tech. Rept. No. 169, Dept, of Elec. Engg., Princeton Univ., Princeton, NJ, 1975.
- Kildall, Gary A. A Unified Approach to Global Program Optimization, in [POPL73], pp. 194-206.
- Wikipedia - Post correspondence problem
- Muchnick and Steven S. Advanced compiler design and implementation.
- Aho, Alfred V. Compilers: principles, techniques, & tools.
- [[compiler/basics/lattice/lattice_theory|格论]]
- [[compiler/data-flow-analysis/intro/data-flow-analysis-intro|数据流分析基础]]
- [[compiler/data-flow-analysis/reaching-definitions/reaching-definitions|到达定值]]